
Production Outage: MySQL server is running with the --read-only option
I recently solved a production outage for a client. The following is a brief summary of the troubleshooting effort and resolution.
What I was Told
The application was written in Java, runs in Elastic Container Service (ECS), and utilizes Amazon Aurora RDS.
The following error message is all the information I received from the client.
PreparedStatementCallback; uncategorized SQLException for SQL [UPDATE as_target_allocation SET id = ?, user_id = ?, index_id = ?, allocation_1 = ?, allocation_2 = ?, allocation_3 = ?, allocation_4 = ?, allocation_5 = ? WHERE id = ?]; SQL state [HY000]; error code [1290]; The MySQL server is running with the --read-only option so it cannot execute this statement; nested exception is java.sql.SQLException: The MySQL server is running with the --read-only option so it cannot execute this statement
Troubleshooting Steps
Since the application had been running correctly before failing, I knew that the MySQL server was not actually running in read-only mode.
I started the troubleshooting process by reviewing the application logs in CloudWatch, and I found the above error message and no other relevant records.
I used the AWS console to view the RDS Cluster. The account had an RDS cluster running with a Primary and one Replica instance.
I reviewed the Task Definition that defines the application's runtime environment and found that an environment variable was used to pass the database endpoint to the application. The endpoint was in the following format.
mydbinstance.123456789012.us-east-1.rds.amazonaws.com:3306
When the primary instance in an Aurora Cluster fails, a replica instance will become the new primary. The endpoint utilized in the Task Definition was to a specific instance, a failover occurred, and that instance was no longer the primary. When the application attempted to write to the database, it threw an exception.
The fix was modifying the Task Definition to pass the Cluster Endpoint instead of an Instance Endpoint.
Explanation
The application was using Instance 1 Endpoint in the below diagram. This worked for a long time because Instance 1 was the Primary.
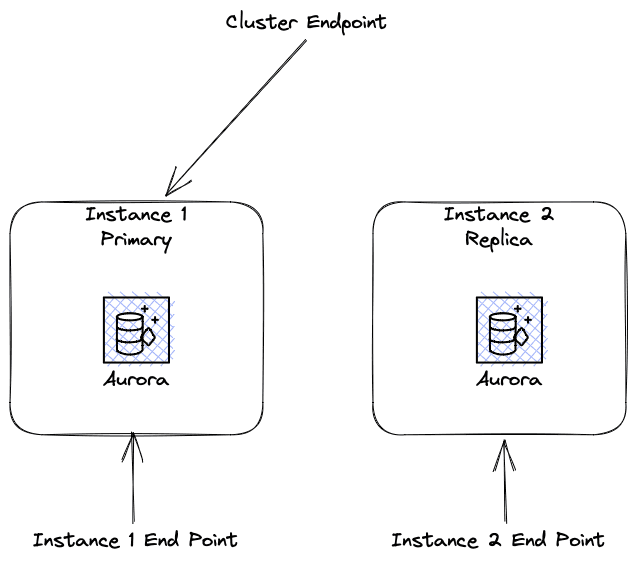
The RDS Cluster experienced a failover event and Instance 1 was now a Replica. If the application had been using the Cluster Endpoint the application would have switched to the new Primary automatically.
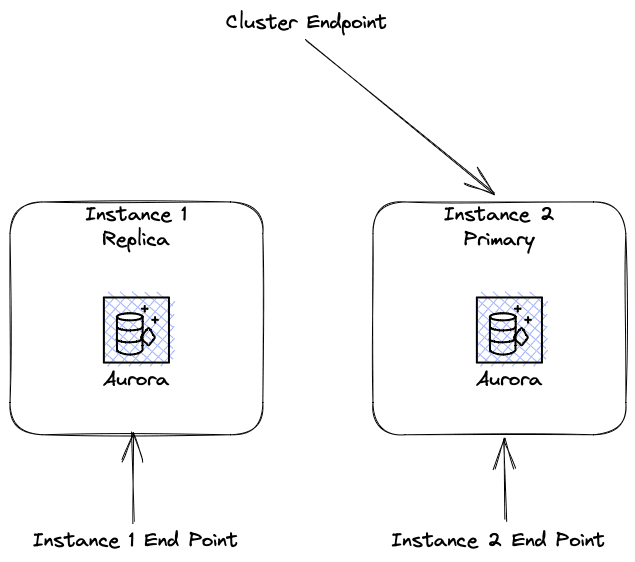
You can read about the types of RDS Endpoints here: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html#Aurora.Overview.Endpoints.Types